從kaggle下載資料集之後,可以直接
import需要的套件
df = pd.read_csv('/titanic_data.csv')
載入資料集
df.head()

可以看到資料及包含名字、船票等級、是否生存、性別、年齡、上同為兄弟姐妹或配偶的數目、同為家族的父母及小孩的數目、船票編號、價格、登船港口
df.isnull().sum()
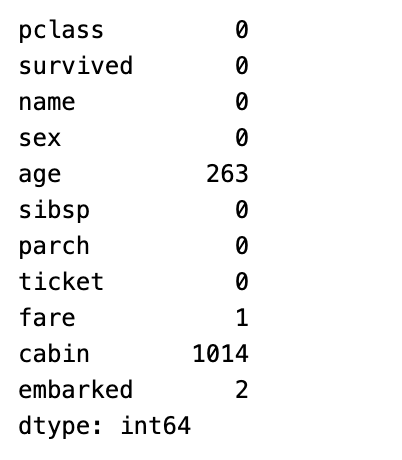
可以看到有哪些資料是有缺漏的,其中年齡和票價是最多缺漏的
在資料前處理的部分,可以刪除不需要的欄位、處理遺失資料,也可以用DAY7的方法將登船港口改為one-hot編碼
如下圖
再將處理好的資料分割為訓練及測試資料及就完成資料前處理了

